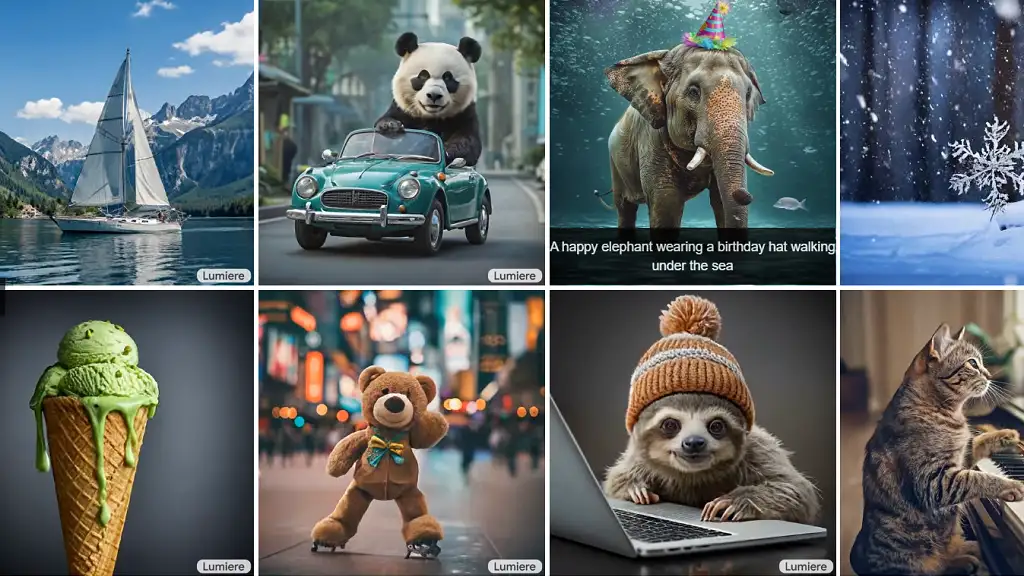
Digital video is a much more complex field than static image processing. And so is its creation with tools that include artificial intelligence models.
For this reason, the appearance of Lumiere, a text-to-video dissemination model developed by Google Research, still in the research process, which uses a different architecture than those that already exist on the market and which are based on the synthesis of frames, causes admiration. distant from each other on the timeline completed with image super-resolution techniques, which can result in a lack of fluidity and realism.
In contrast, Lumiere presents the Space-Time U-Net (STUNet) architecture, which allows the model to perform single-step processing over the entire temporal duration, generating videos in which it captures the text instruction in a very consistent way. (or prompt). At this stage of the project, the videos are 5 seconds long with a high resolution quality.
But Google Research’s Lumiere can also generate videos from individual images if given instructions with style references or other custom details.
In this context, it is able to build animations in specific regions of an individual image while the rest remains static; It can also generate image sequences based on specific styles, and use inpainting techniques, both to alter certain visual elements of the video and to restore incomplete videos by filling in the missing parts.
How to appreciate the work done with Lumiere?
According to the project paper, Lumiere is aimed at novice users who wish to generate audiovisual content in a creative and flexible way. However, they emphasize the risks that this technology brings, which, if it falls into the wrong hands, can lead to the massive generation of false or inappropriate content. If you want to appreciate the work done with Lumiere you just have to visit its page hosted on GitHub https://lumiere-video.github.io/.
Image: Lumiere